DRAM页映射到BANK中的两种形式
DRAM页映射到BANK中的两种形式
在之前的一篇博文上,我分析了DRAM的物理结构与从bank中存取数据的方式。这里我继续这个话题,并引入一种新式的内存存取数据的方式:Permutation-based Page Interleaving。
当CPU发送物理内存地址给内存的时候需要首先发送给memory controller,然后由memory controller将其翻译成内存地址,也就是以DIMM Rank Chip Bank为单位的地址形式,如下图所示:
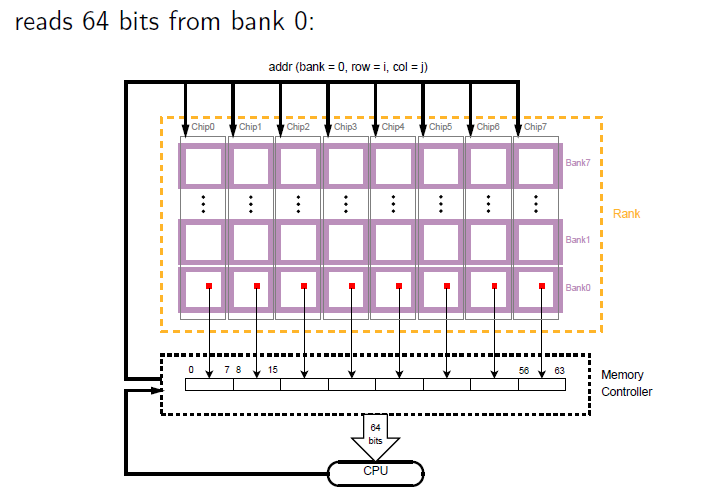
我们知道CPU对Memory的读写要经过cache,在这里可以认为CPU与cache是一体的,读到了cache也就等于被CPU使用。传统的memory与cache的关系是多路并联、单路并联,也就是说一系列的内存物理地址,被分割成了tag段,每个tag段内的每个内存地址映射到不同cache line中。
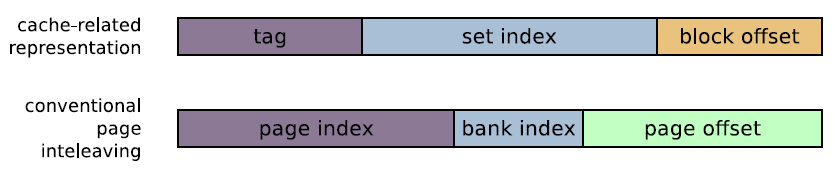
也就是说不同tag段的相同set index会被映射到同一个cache line中,而最后的block offset正是cache line的大小,也就是说这个物理地址中的内容放到cache line中正是cache line的大小,然后我们将这个位数变化一下,就是传统物理地址对应三个部分,page index,bank index,page offset。而其中bank index的信息是具体的硬件实现(硬件生产商不会对外公布这种参数),一般我们使用软件的方式来测试bank位!
这里的page不是我们常规意义上的物理页,而是第一个图中以bank 与row组成的一行称为page。
下面我们来做一个推定:比如tag值不同,后面set index,block offset两个字段相同的两个物理地址,必定映射同一个cache line。转换到下面的DRAM的页模式,set index相同,那么bank index一定相同,也就是说两个数据处于同一个bank中,又因为tag不同,那么page index不同,意味着不属于同一个row,而每个bank只有一个row buffer,这样必然导致L3(CPU最后一级cache)无法命中,导致 L3 cache conflict miss!
举例:
double x[T], y[T], sum;
for(i = 0; i less T; i++);
sum += x[i] * y[i];
若x[0] 和y[0] 的距离是L3 cache 大小的倍数,必然会导致读取x[i],y[i]发生L3 cache conflict miss!CPU不得不每次讲L3 cache清空,读取新的数据,这样必然大大增加了数据访问的延迟!
为了避免这种情况工程师提出了一种新的内存page交叉访问方式Permutation-based Page Interleaving Scheme,首先我们看这个算法如何降低了 L3 cache conflict miss。
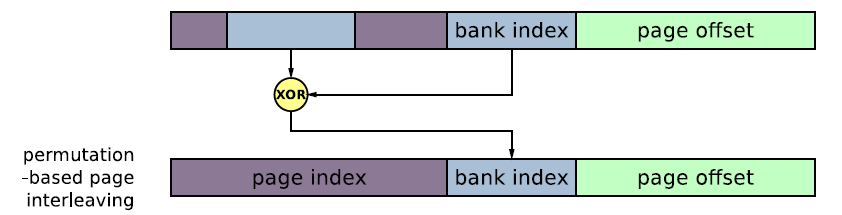
他在传统物理地址对应的banks存取上,使用tag的一些位与bank index做异或运算,这样就可以大大降低内存页交叉访问带来的L3 conflict miss,不同tag的相同bank index会被映射到不同的bank中!
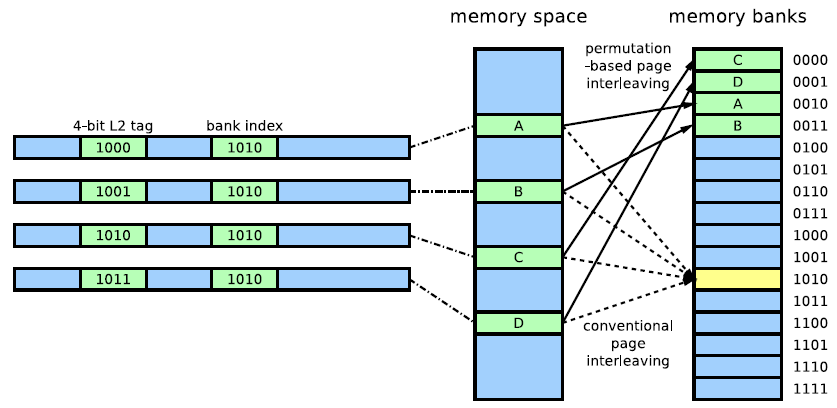
而我们知道每个bank都有一个row buffer,只要我们保证程序局部性存取的数据在不同row buffer中,这样就意味着row buffer的数据可以长时间存在,不同频繁的清空,当需要这些数据,直接从row buffer中读取到memory controller就可以了。而程序的局部性并没有被破坏,仍然存在在一个DRAM page!
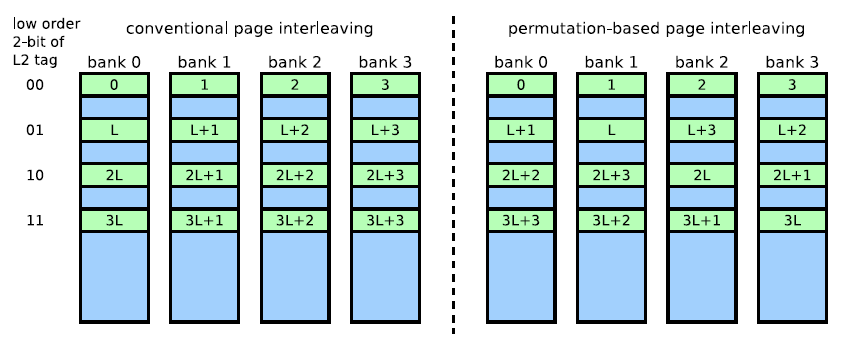
这两种方式长时间存在于DRAM交叉存取bank中,有时候我们在测试Bank位会遇到这两种方式,因此我们必须使用特定工具去检测决定bank位的index,如过检测bank index非常多,就要考虑是否是XOR交叉存取方式了!
论文:http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=898056