物理内存管理:伙伴系统page分裂函数分析
物理内存管理:伙伴系统page分裂函数分析
在快速分配函数中,大部分代码都是一些具体策略的实现,包括watermark,NUMA,公平分配ALLOC_FAIR等。真正与buddy system有关的就是buffered_rmqueue()函数。
我们看到当进入到这个函数,会先对order进行一个判断,如果order==0,则kernel不会从伙伴系统分配,而是从per-cpu缓存加速请求的处理。如果缓存为空就要调用rmqueue_bulk()函数填充缓存,道理还是从伙伴系统中移出一页,添加到缓存。
当传入的order>0时,则调用_rmqueue()从伙伴系统中选择适合的内存块,有可能会将大的内存块分裂成为小的内存块,用来满足分配请求。
static inline
struct page *buffered_rmqueue(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
gfp_t gfp_flags, int migratetype)
{
unsigned long flags;
struct page *page;
bool cold = ((gfp_flags & __GFP_COLD) != 0);
again:
if (likely(order == 0)) {
...
} else {
if (unlikely(gfp_flags & __GFP_NOFAIL)) {
WARN_ON_ONCE(order > 1);
}
spin_lock_irqsave(&zone->lock, flags);
page = __rmqueue(zone, order, migratetype);
spin_unlock(&zone->lock);
if (!page)
goto failed;
__mod_zone_freepage_state(zone, -(1 << order),
get_freepage_migratetype(page));
}
...
}
...
static struct page *__rmqueue(struct zone *zone, unsigned int order,
int migratetype)
{
struct page *page;
retry_reserve:
page = __rmqueue_smallest(zone, order, migratetype);
if (unlikely(!page) && migratetype != MIGRATE_RESERVE) {
page = __rmqueue_fallback(zone, order, migratetype);
if (!page) {
migratetype = MIGRATE_RESERVE;
goto retry_reserve;
}
}
trace_mm_page_alloc_zone_locked(page, order, migratetype);
return page;
}
上面说的buffered_rmqueue()是进入伙伴系统的前置函数,而__rmqueue是进入伙伴系统的最后一个包装函数,通过这个函数,__rmqueue_smallest()会扫描当前zone下面的空闲区域。
如果不能通过这种方式分配出空闲页,那么系统会调用__rmqueue_fallback()来遍历不同的迁移类型,试图找出不同的迁移类型中空闲的page。这里我们不会仔细分析,但是我们看一下__rmqueue_fallback()的遍历头就能发现端倪。kernel会从start_migratetype迁移类型考虑备用列表的不同迁移类型,具体可以查看http://lxr.free-electrons.com/source/mm/page_alloc.c#L1036。
static inline struct page *
__rmqueue_fallback(struct zone *zone, unsigned int order, int start_migratetype)
{
struct free_area *area;
unsigned int current_order;
struct page *page;
int migratetype, new_type, i;
/* Find the largest possible block of pages in the other list */
for (current_order = MAX_ORDER-1;
current_order >= order && current_order <= MAX_ORDER-1;
--current_order) {
for (i = 0;; i++) {
migratetype = fallbacks[start_migratetype][i];
...
__rmqueue_smallest()函数传入的参数有order,kernel会遍历当前zone下面从指定order到MAX_ORDER的伙伴系统,这个时候迁移类型是指定的,如图: 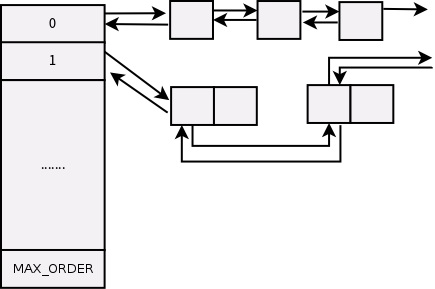
static inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
if (list_empty(&area->free_list[migratetype]))
continue;
page = list_entry(area->free_list[migratetype].next,
struct page, lru);
list_del(&page->lru);
rmv_page_order(page);
area->nr_free--;
expand(zone, page, order, current_order, area, migratetype);
set_freepage_migratetype(page, migratetype);
return page;
}
return NULL;
}
我们看到kernel会提取出当前zone下面的struct free_area,我们知道struct free_area是上图整体的一个结构,然后我们按照order可以找到指定的free_list结构,这个结构链接了所有系统中空闲page。
找到这个page,则将这个page从list上面删除,然后rmv_page_order()可也将page的标志位PG_buddy位删除,表示这个页不包含于buddy system。
将这个page所在的nr_free自减,之后调用expand()函数,这个函数存在的意义就是在高阶order分配了一个较小的page,但同时低阶order又没有合适的页分配。
static inline void expand(struct zone *zone, struct page *page,
int low, int high, struct free_area *area,
int migratetype)
{
unsigned long size = 1 << high;
while (high > low) {
area--;
high--;
size >>= 1;
.....
list_add(&page[size].lru, &area->free_list[migratetype]);
area->nr_free++;
set_page_order(&page[size], high);
}
}
进入到expand()函数,这个函数是从current_order到请求order倒序遍历,函数的核心是通过current_order折半分裂,分裂完之后,将空闲的page挂到相同的order阶上面的free_area,然后nr_free++,set_page_order()作用是对于回收到伙伴系统的的内存的一个struct page实例中的private设置分配阶,并且设置PG_buddy。
完成伙伴系统的高阶page分裂。
PLKA: Page190