内存条物理结构分析
内存条物理结构分析
我们经常接触物理内存条,如下有一根DDR的内存条,我们可以看到这个内存条上面有8个黑色的内存颗粒,在高端服务器上面通常会带有ECC校验,所以会存在9个黑色的内存颗粒,其中一个的内存颗粒是专门做ECC校验的。

从概念的层次结构上面分为:Channel > DIMM > Rank > Chip > Bank > Row/Column
我们可以把DIMM作为一个内存条实体,我们知道一个内存条会有两个面,高端的内存条,两个面都有内存颗粒。所以我们把每个面叫做一个Rank,也就是说一个内存条会存在Rank0和Rank1。
拿rank0举例,上面有8个黑色颗粒,我们把每个黑色颗粒叫做chip。再向微观走,就是一个chip里面会有8个bank。每个bank就是数据存储的实体,这些bank就相当于一个二维矩阵,只要声明了column和row就可以从每个bank中取出8bit的数据。
我们之前会经常说双通道,说白了就是一个DIMM就是一个通道,两个DIMM组成双通道,分别由两个Memory Controller控制。
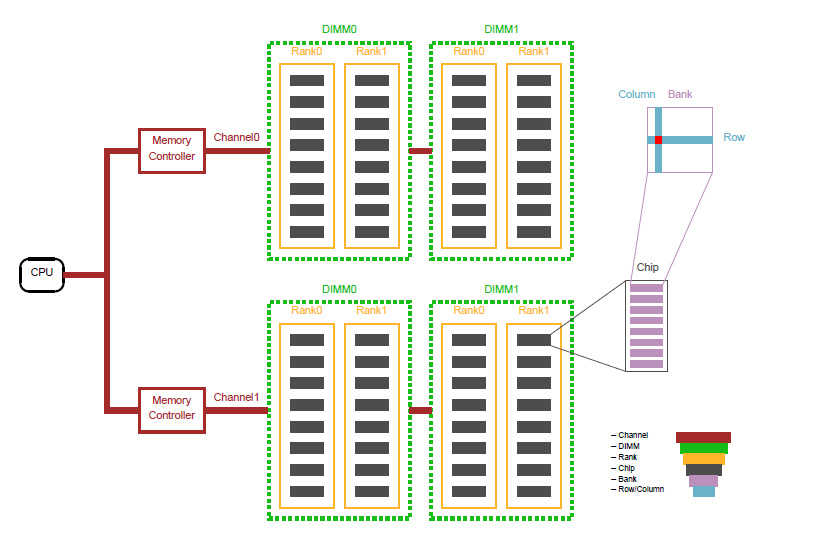
我们可以看到两个DIMM0 DIMM0组成双通道,两个DIMM1 DIMM1组成双通道。
下面先来解释memory controllers如何从rank中取数据,上面说的都是物理结构,下面说内存的逻辑结构。因为每个rank下面会有很多chip,而每个chip又包括bank0、bank1、bank2等,在memory controllers看来每次发数据,都会同时发送给所有chip下的某个bank,并声明row和col。
以从bank0为例:
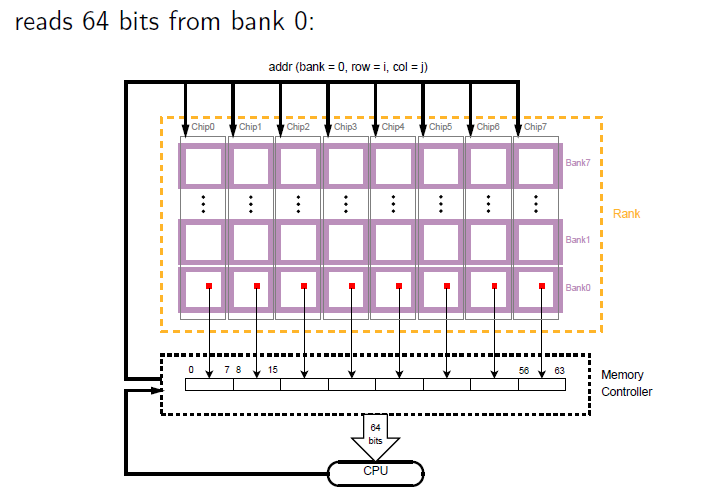
###每个chip的bank0 的同一地点(row=i col=j)都会被读出8bit,那么8个chip就会同时读出64bit,然后由memory controllers传送给cpu,也就是8byte。
在memory controllers看来,每个bank存在于每个chip中,如上图所示,可以把每个chip里面的小bank连成一行,b看作成一个大的bank。然后从大的bank中读取数据。
每个bank有一个row bufffer,作为一个bank page,所有bank共享地址、数据总线,但是每个channel有他们自己的地址、数据总线。正因为有buffer,所以每次bank都会预读64bit的数据。
上面看到的是分解的操作,事实上,为了加快memory的读写,体系结构中引入了流水线,也就意味着memory controllers可以同时读64byte,也就是8次这样的操作。写入到buffer中,这就是局部性原理。如果我们程序猿不尊重这个规则,也就迫使bank的buffer每次取值都必须清空当前的缓冲区,重新读数据,降低数据的访问速度。
###设计弊端:
那么内存在多核平台的表现就取决于数据位于哪个bank之中,在给定的时间kernel如何访问多核之间共享的bank,最好的一种情况是每个core都只访问自己的bank,互不干扰。最坏的一种情况就是所有的core都访问同一个bank,只能同时有一个core访问该bank,其他core必须等待这个bank的,这样的话造成memory access的delay,考虑一种情况:如果多个进程在多个bank中都有自己的数据,controllers不得不每次清空row buffer,造成性能损失。而且使得时间分析变得不确定!
由于memory controllers内侧对于bank的操作对外透明,row col bank这些指令信息属于内存地址(memory controllers将physics address翻译成内存地址)。研究memory controllers向bank发送读信息的编码格式,我们会发现row与col位之间会有bank 位的介入,也就意味着对于bank的访问会分割到几个bank同时进行。
如果我们想把进程在内存中的数据限制在某个bank中,就要测试这种内存地址格式,目前可以palloc自带的工具进行测试,测试bank位到底存在于内存地址的哪几位。
目前系统都是多核,而且kernel将memory视为一个整体。不会区分分配的资源来自于哪个bank,所以数据分配的确定位置是不可预期的。而且目前memory controllers被配置为分割的bank来提高bank访问的并行度(一个程序分配的内存在每个bank中都存在)。但是这个导致一个问题:肯定有好几个进程数据存在于当前bank。当bank中出现multiple error时,我们无法准确定位这个错误来自于哪个进程!