Thinking in Memeory Barrier
Memory Barriers 的一些思考
之前由于各种原因blog停更了半个月,现在回到正常环境下。
我们都知道在多处理器环境下,我们会遇到Memory Barriers,其实说白了,就是数据的不一致性,说的更加精确点,就是cache的不一致性,因为各种architecture 不同,x86与ARM不同,在x86下,Intel与AMD又不同,所以我们要搞清cpu与cache的不同结构,之前我们知道cache分为N路组相联(N-way set associative)。在取值的时候,中间位负责区分是哪一路,在这篇文章中讲的很详细:
http://lzz5235.github.io/2013/12/10/storage.html
######不过x86的mb。x86 CPU会自动处理store顺序,所以smp_wmb()原语什么也不做,但是load有可能乱序!
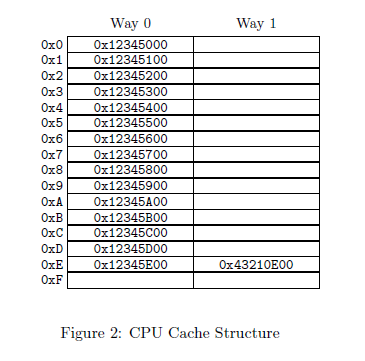
上图我们可以看出是两路。
#####Memory Barriers 产生的原因主要是 CPU硬件设计为了提高指令的执行速度,增设了两个缓冲区(store buffer, invalidate queue)。这个两个缓冲区可以避免CPU在某些情况下进行不必要的等待,从而提高速度,但是这两个缓冲区的存在也同时带来了新的问题。
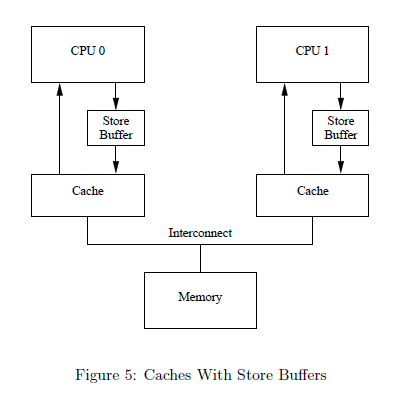
那就是cache的不一致性!
解决这种不一致性,就是使用Cache-Coherence Protocols。类似于tcp的感觉,cpu0发出read ,cpu1响应read response。
这个协议主要有四个状态:
modified状态:该cache-line包含修改过的数据,内存中的数据不会出现在其他CPU-cache中,此时该CPU的cache中包含的数据是最新的
exclusive状态:与modified类似,但是数据没有修改,表示内存中的数据是最新的。如果此时要从cache中剔除数据项,不需要将数据写回内存
shared状态:数据项可能在其他CPU中有重复,CPU必须在查询了其他CPU之后才可以向该cache-line写数据
invalid状态:表示该cache-line空
这四个状态经常转换
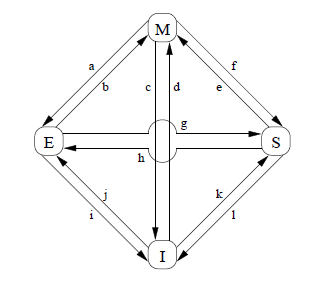
这个协议定义了很多个消息:
read: 包含要读取的CACHE-LINE的物理地址
read response: 包含READ请求的数据,要么由内存满足要么由cache满足
invalidate: 包含要invalidate的cache-line的物理地址,所有其他cache必须移除相应的数据项
invalidate ack: 回复消息
read invalidate: 包含要读取的cache-line的物理地址,同时使其他cache移除该数据。需要read response和invalidate ack消息
writeback:包含要写回的数据和地址,该状态将处于modified状态的lines写回内存,为其他数据腾出空间
举个例子:
1 a = 1;
2 b = a + 1;
3 assert(b == 2);
假设初始时a和b的值都是0,a处于CPU1-cache中,b处于CPU0-cache中。如果按照下面流程执行这段代码:
1 CPU0执行a=1;
2 因为a在CPU1-cache中,所以CPU0发送一个read invalidate消息来占有数据
3 CPU0将a存入store buffer
4 CPU1接收到read invalidate消息,于是它传递cache-line,并从自己的cache中移出该cache-line
5 CPU0开始执行b=a+1;
6 CPU0接收到了CPU1传递来的cache-line,即“a=0”
7 CPU0从cache中读取a的值,即“0”
8 CPU0更新cache-line,将store buffer中的数据写入,即“a=1”
9 CPU0使用读取到的a的值“0”,执行加1操作,并将结果“1”写入b(b在CPU0-cache中,所以直接进行)
10 CPU0执行assert(b == 2); 失败
出现问题的原因是我们有两份”a”的拷贝,一份在cache-line中,一份在store buffer中。硬件设计师的解决办法是“store forwarding”,当执行load操作时,会同时从cache和store buffer里读取。也就是说,当进行一次load操作,如果store-buffer里有该数据,则CPU会从store-buffer里直接取出数 据,而不经过cache。因为“store forwarding”是硬件实现,我们并不需要太关心。
考虑下面的代码:
void foo(void)//cpu0 b
{
a = 1;
b = 1;
}
void bar(void)//cpu1 a
{
while (b == 0) continue;
assert(a == 1);
}
假设变量a在CPU1-cache中,b在CPU0-cache中。CPU0执行foo(),CPU1执行bar(),程序执行的顺序如下:
1 CPU0执行 a = 1; 因为a不在CPU0-cache中,所以CPU0将a的值放到store-buffer里,然后发送read invalidate消息
2 CPU1执行while(b == 0) continue; 但是因为b不再CPU1-cache中,所以它会发送一个read消息
3 CPU0执行 b = 1;因为b在CPU0-cache中,所以直接存储b的值到store-buffer中
4 CPU0收到 read 消息,于是它将更新过的b的cache-line传递给CPU1,并标记为shared
5 CPU1接收到包含b的cache-line,并安装到自己的cache中
6 CPU1现在可以继续执行while(b == 0) continue;了,因为b=1所以循环结束
7 CPU1执行assert(a == 1);因为a本来就在CPU1-cache中,而且值为0,所以断言为假
8 CPU1收到read invalidate消息,将并将包含a的cache-line传递给CPU0,然后标记cache-line为invalid。但是已经太晚了
就是说,可能出现这类情况,b已经赋值了,但是a还没有,所以出现了b = 1, a = 0的情况。对于这类问题,硬件也无法解决,因为CPU无法知道变量之间的关联关系。所以硬件设计者提供了memory barrier指令,让软件来告诉CPU这类关系。
解决方法是修改代码如下:
void foo(void)
{
a = 1;
smp_mb();
b = 1;
}
###smp_mb()指令可以迫使CPU在进行后续store操作前刷新store-buffer。以上面的程序为例,增加memory barrier之后,就可以保证在执行b=1的时候CPU0-store-buffer中的a已经刷新到cache中了,此时CPU1-cache中的a 必然已经标记为invalid。对于CPU1中执行的代码,则可以保证当b==0为假时,a已经不在CPU1-cache中,从而必须从CPU0- cache传递,得到新值“1”。
上面的例子是使用memory barrier的一种环境,另一种环境涉及到另一个缓冲区,确切的说是一个队列——“Invalidate Queues”。
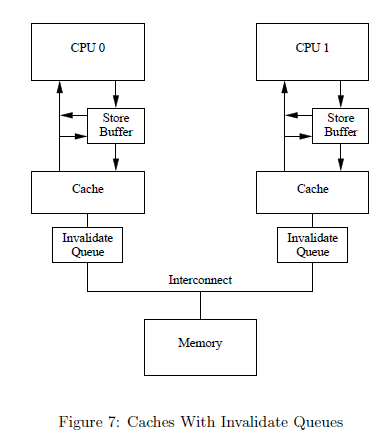
store buffer一般很小,所以CPU执行几个store操作就会填满。这时候CPU必须等待invalidation ACK消息,来释放缓冲区空间——得到invalidation ACK消息的记录会同步到cache中,并从store buffer中移除。同样的情形发生在memory barrier执行以后,这时候所有后续的store操作都必须等待invalidation完成,不论这些操作是否导致cache-miss。解决办法 很简单,即使用“Invalidate Queues”将invalidate消息排队,然后马上返回invalidate ACK消息。不过这种方法有问题。_
考虑下面的情况:
void foo(void)//CPU0 b
{
a = 1;
smp_mb();
b = 1;
}
void bar(void)//CPU1
{
while (b == 0) continue;
assert(a == 1);
}
a处于shared状态,b在CPU0-cache内。CPU0执行foo(),CPU1执行函数bar()。执行操作如下:
1 CPU0执行a=1。因为cache-line是shared状态,所以新值放到store-buffer里,并传递invalidate消息来通知CPU1
2 CPU1执行 while(b==0) continue;但是b不再CPU1-cache中,所以发送read消息
3 CPU1接受到CPU0的invalidate消息,将其排队,然后返回ACK消息
4 CPU0接收到来自CPU1的ACK消息,然后执行smp_mb(),将a从store-buffer移到cache-line中
5 CPU0执行b=1;因为已经包含了该cache-line,所以将b的新值写入cache-line
6 CPU0接收到了read消息,于是传递包含b新值的cache-line给CPU1,并标记为shared状态
7 CPU1接收到包含b的cache-line
8 CPU1继续执行while(b==0) continue;因为为假所以进行下一个语句
9 CPU1执行assert(a==1),因为a的旧值依然在CPU1-cache中,断言失败
10 尽管断言失败了,但是CPU1还是处理了队列中的invalidate消息,并真的invalidate了包含a的cache-line,但是为时已晚
可以看出出现问题的原因是,当CPU排队某个invalidate消息后,在它还没有处理这个消息之前,就再次读取该消息对应的数据了,该数据此时本应该已经失效的!!!
解决方法是在bar()中也增加一个memory barrier:
void bar(void)
{
while (b == 0) continue;
smp_mb();
assert(a == 1);
}
此处smp_mb()的作用是处理“Invalidate Queues”中的消息,于是在执行assert(a==1)时,CPU1中的包含a的cache-line已经无效了,新的值要重新从CPU0-cache中读取。
memory bariier还可以细分为“write memory barrier(wmb)”和“read memory barrier(rmb)”。rmb只处理Invalidate Queues,wmb只处理store buffer。
可以使用rmb和wmb重写上面的例子:
void foo(void)
{
a = 1;
smp_wmb();
b = 1;
}
void bar(void)
{
while (b == 0) continue;
smp_rmb();
assert(a == 1);
}
下面在这种体系结构下:
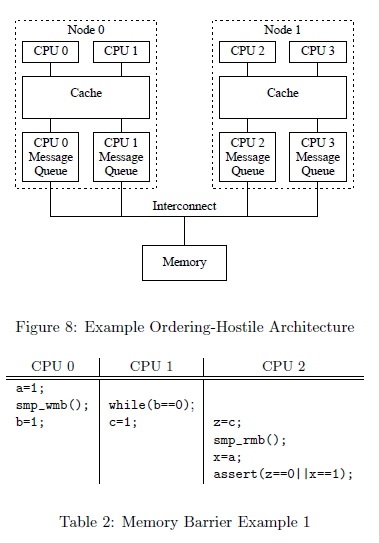
#####首先看一下结构图CPU0 CPU1共享cache,而CPU2独立于CPU0 CPU1!
CPU 0,1,2 同时执行上述三个代码片段,a,b,c的初始值都为0
- 假设CPU0经历了许多 cache misses ,故CPU0 的 Message Queue 是满的,CPU1的操作和其cache保持一致,故CPU1 的 Message Queue 是空的
- CPU0 赋值a b 的操作在node0立即执行(a b不在其cache中),但是由于其Message Queue 是满的,__故操作会被先前的invialid阻塞(该操作对于CPU1是可见的)__,也就是说CPU0没有发出read invalidn,CPU2中仍以为a = 0 ,(CPU2取得a的值,必须通过read指令,但是此刻不需要read,因为CPU2没有收到CPU0的invalid!)而CPU1执行的c赋值操作会立刻执行(CPU1的操作和其cache保持一致)。
-
因此,在CPU0分配a之前CPU2会读到CPU1分配的c值,即z=1 x = 0 故assert(z==0 x==1)不能执行。
同理Memory Barrier也发生在下面的情况
CPU0 CPU1 CPU2
a=1; while(a==0);
smp_mb(); y=b;
b=1; smp_rmb();
x=a;
assert(y==0 || x==1)
CPU0 赋值a 的操作在node0立即执行(a 不在其cache中),但是由于其Message Queue 是满的,故操作会被先前的invialid阻塞(该操作对于CPU1是可见的),然而CPU1执行的b赋值操作会立刻执行,又因为CPU1 的Message Queue为空,所以CPU2可以立即收到b的invialid,而更新b在CPU2 cache中的值!
##最后这个例子有些问题!!!求解
CPU0 CPU1 CPU2
a=1;
smp_wmb();
b=1; while(b==0); while(b==0);
smp_mb(); smp_mb();
c=1; d=1;
while(c==0);
while(d==0);
smp_mb();
e=1; assert(e==0 || a==1)
CPU 0,1,2 同时执行上述三个代码片段,所有变量的初始值都为0
-
在CPU0分配 b的值之前 CPU 1、2 都不能执行第五行(当CPU0执行b=1时,b对CPU 1、2是无效的,并且smp_mb()保证将b的值写回)
-
一旦CPU 1、2执行smp_mb(),他们就都能保证看到a=1,b=1执行成功
-
CPU0 的smp_mb()和CPU 1、2的是成对使用的,这个类似于锁变量,能够保证了CPU 1、2在获取a=1之前,e=1没有被执行(e=1包括load和store两部分,而a==1之包括load,所以)
####rmb只处理Invalidate Queues,wmb只处理store buffer。也就是说上面代码第二句只是刷新了buffer与cache的一致性,没有提到通知CPU2,所以CPU2不知道a值改变了!
下面是我对这个example的理解:
1 CPU0执行a=1。因为cache-line是shared状态,所以a的新值放到store-buffer里,并传递invalidate消息来通知CPU2
2 CPU1执行 while(b==0) continue;CPU0与CPU1处于同一个node0,所以b立刻看到b值的变化。
3 CPU2接受到CPU0的invalidate消息,将其排队,然后返回ACK消息
4 CPU0接收到来自CPU2的ACK消息,然后执行smp_wmb(),将a从store-buffer移到cache-line中.wmb只处理store buffer。
5 CPU0执行b=1;因为已经包含了该cache-line,所以将b的新值写入cache-line
6 CPU0接收到了read消息,于是传递包含b新值的cache-line给CPU2,并标记为shared状态
7 CPU1接收到包含b的cache-line,CPU2接收到包含b的cache-line
8 CPU1继续执行while(b==0) continue;因为为假所以进行下一个语句,CPU2继续执行while(b==0) continue;因为为假所以进行下一个语句
9 CPU1,CPU2执行smp_mb(),因为a的旧值依然在CPU2-cache中,强制让CPu2从CPU0获取a值。
10 然后将c,d的值存入到store-buffer里,并传递invalidate消息来通知CPU0,CPU1,CPU2 11 while(c==0);while(d==0);为假通过。强制让e的赋值在c,d的赋值以下
12,给e赋值,执行CPU2的assert()通过。
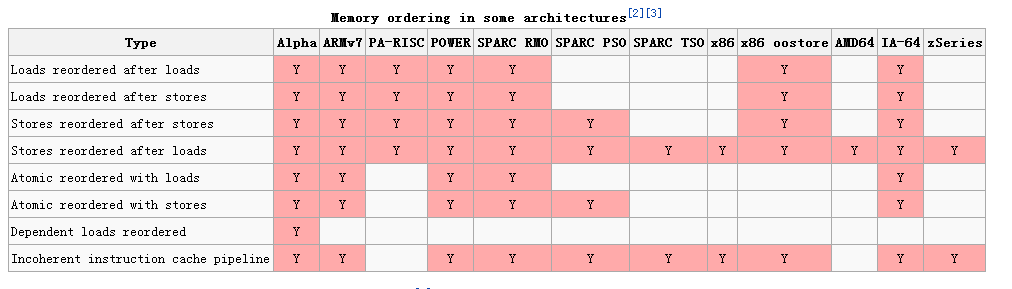
最后我要说一下内存屏障指令在不同体系结构中的·不同形式,因为我们关注x86,可以看到x86中Stores reordered after loads与Incoherent instruction cache pipeline是支持的!而smp_mb(),smp_wmb(),smp_rmb()是与指令相关的,在每种体系结构中实现是不同的。对于kernel开发者与应用层开发者,我们不必关心memory order,但是从硬件角度了解指令的执行流程是必要的。
参考:
https://www.kernel.org/doc/Documentation/memory-barriers.txt