字符编码浅析
字符编码浅析
最近在linux与windows上面做切换,经常会遇到乱码问题,又联想起很多因为字符解析失败,最后debug出来是因为字符编码的问题后,准备仔细研究这一块奇怪的东东。
我主要是使用汉语,所以与我们息息相关的编码时gb2312、GBK和UTF系列。
GB2312是最早的汉语标准,但是最大的问题是收录的汉字太少,导致许多复杂的函数无法在机器中表示。之后Microsoft使用GB2312未使用的编码空间,拓展了收录的字符数。
但是真正的国家标准是GB18030,它收录了7万多个汉字,目前的国内软件都必须支持这个字符集。
- 我们都知道ASCII码在电脑中用1 byte来表示,比如 strlen(“l123″),就返回一个字符长度4,而汉字在电脑中使用2 byte来表示,也就是strlen(“李123″)返回5!
如果在一个页面中存在多种语言,那在我们看来就是一堆乱码!所以unicode出现了,但是unicode又会分成很多字符标准:
utf-16 的实现是每个字符有2 byte来表示,但是这种编码方式没有运用在浏览器中。 在windows中使用宽字符进行表示,也是说下面代码虽然有汉字,但是每个s元素都是2 byte,最后的len也还是4!
wchar_t s[10];
int len=0;
wcscpy(s, L“李123”);
len = wcslen(s);
wchar_t 其实是 unsigned short,一个 16-bit,C 语言所有的 strxxx 都有相对应的 wcsxxx,字符串前面加上 L,代表宽字符。
- utf-16 的实现是每个字符由4 byte来表示,太占空间,没有人使用。
- utf-8是我们现在通用的一种字符表示编码,每个字符是可变长度的。
每个字可能是 1~6个bytes (2003年后删减剩下 1~4 个 bytes)
- US-ASCII (0 ~ 127) : 1-byte
- 部分各国字母: 2-byte (例如希腊字母,西里尔字母…)
- 其它常用字 : 3-byte (大部分的汉字)
- 极少用字 : 4~6-byte (包含罕见汉字 ,麻将牌…)
也就是说平时的英文数字大概一个字符一个byte,而汉字 3 byte。
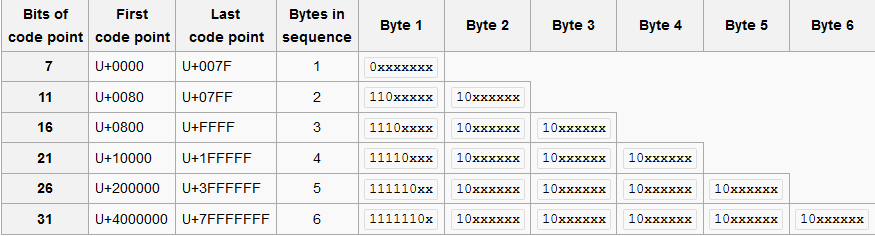
上面这幅图表示的是utf8的表示方式[1],我们可以看到电脑在寻找这个字符由几个byte主要是看byte 1,有几个1 就有几个byte。
strlen("李123")
上面的代码使用unicode的话就会返回6!下面来分析下大小端与字符编码的关系:
我们都知道小端就是low byte在前,high byte在后,典型使用这种方式就是x86架构。
- 在GB2312中 李123 = e6 9d 8e 31 32 33,那么他在小端机器中,文档中打开也是这个样子:e6 9d 8e 31 32 33
- 在utf-16中 李123 = 67 4e 00 31 00 32 00 33 在文档中打开:4e 67 31 00 32 00 33 00。因为他是以两个byte为一个单位。
- 在utf-8中 李123=e6 9d 8e 31 32 33 在文档中打开也是:e6 9d 8e 31 32 33
所以基于上述知识,我们知道在notepad打开一个文档,有时候会读取BOM!BOM 位于文档的开头位置
- FE FF 开头 ->UTF-16 Big Endian
- FF FE 开头 ->UTF-16 Little Endian
- EF BB BF 开头 -> UTF-8
- 都不是,看系统默认编码 (GB2312?)
所以我们在代码读取文档的时候,要小心BOM的存在,BOM 可以告诉你后续内容的编码方式,有时候必须跳过 BOM,不要把 BOM 当成内容一起处理。
在Linux 中解决代码转换问题:iconv,而一些特定的语言例如python使用 str.encode(‘utf-8′)。
I18N:所有的语言都写在外部txt,方便做本地适配,代码也不用重新编译。